1. PIA --> SPD level
The P32 data needs to be saved by the PIA as an internal SPD file at the SPD level . This file ends with ".ISPD".2. Feed the SPD result into IMAP
Start an IDL session from the directory which contains the imap.pro file and the saved SPD file. Then type the following at the IDL prompt. You should have imap.pro saved to a file in advance.3. PIA --> Astrophysical Work --> map constructionIDL> .r imap.proThen follow the comments and questions at the IDL prompt.
IDL> imap,'filename'The imap.pro displays several images at appropriate times to aid the user visually. In addition, five of these displays, one from each of the major sections of program, are saved to imap_result.ps file, so that the user can produce hardcopies easily.
In the end, the user has the option of saving the imap.pro results to a new internal SPD file or exit without saving any changes. The new file has ".ISPD_IMAP" ending to distinguish it from the original PIA result.
Now you can load this new file into the PIA and construct the map as usual. Please note that to read this file into the PIA properly, you need to delete the _IMAP ending. Refer to the PIA User Manual for questions regarding the map construction. Also, you should disable the Flat Fielding with the PIA mapping because IMAP already applied skyflattening.
| 3 | 6 | 9 |
| 2 | 5 | 8 |
| 1 | 4 | 7 |
The pixel arrangement for the C200 detector is as follows.
| 3 | 4 |
| 2 | 1 |
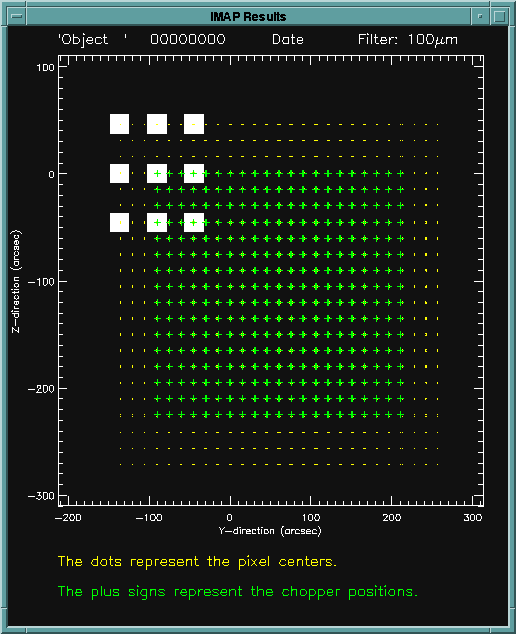
For both diagrams above, the +Y is to the right and +Z is upwards.DISPLAY Displays the individual pixel centers with yellow dots, and the detector centers at each chopper plateau with green plus signs. Above the plot, the name of the object, TDT number, date of observation, and wavelength of the filter used are given. The gray square boxes represent the individual detector pixels for the top left most chopper plateau. These boxes are correctly centered at the pixel centers. However, these are NOT drawn to scale, and the aspect ratio of the display is not correct; this is simply to aid the user with the visualization.
DISPLAY
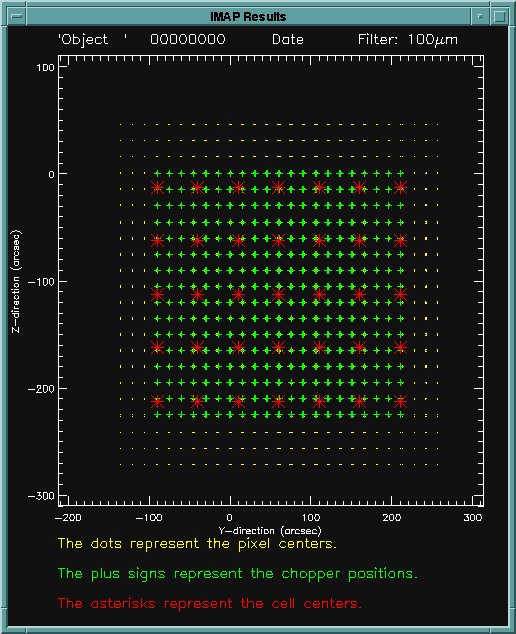
After the number of cells and their locations are calculated, the result
is plotted. As before, the yellow dots represent the pixel centers,
and the green plus signs show the chopper plateaus. Now, the red
asterisks represent the centers of the cells. The cells should not
be too closely spaced.
| Y-cell | Z-cell | Y-center | Z-center | number of valid data points | mean | sigma | number of points flagged |
| number | number | arcsec | arcsec | number | watts | watts | number |
DISPLAY
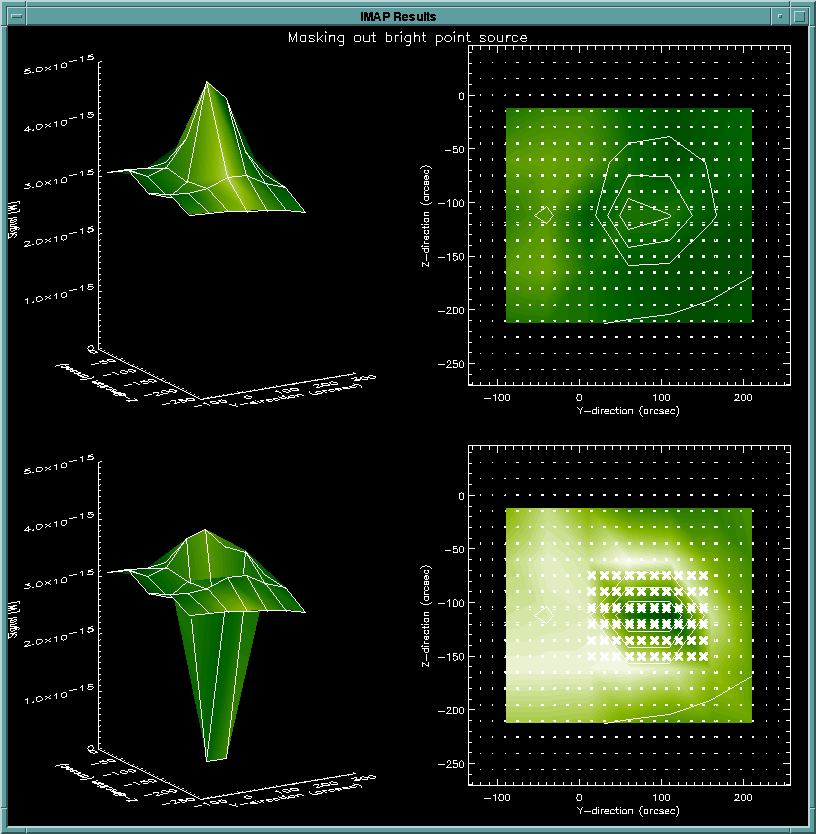
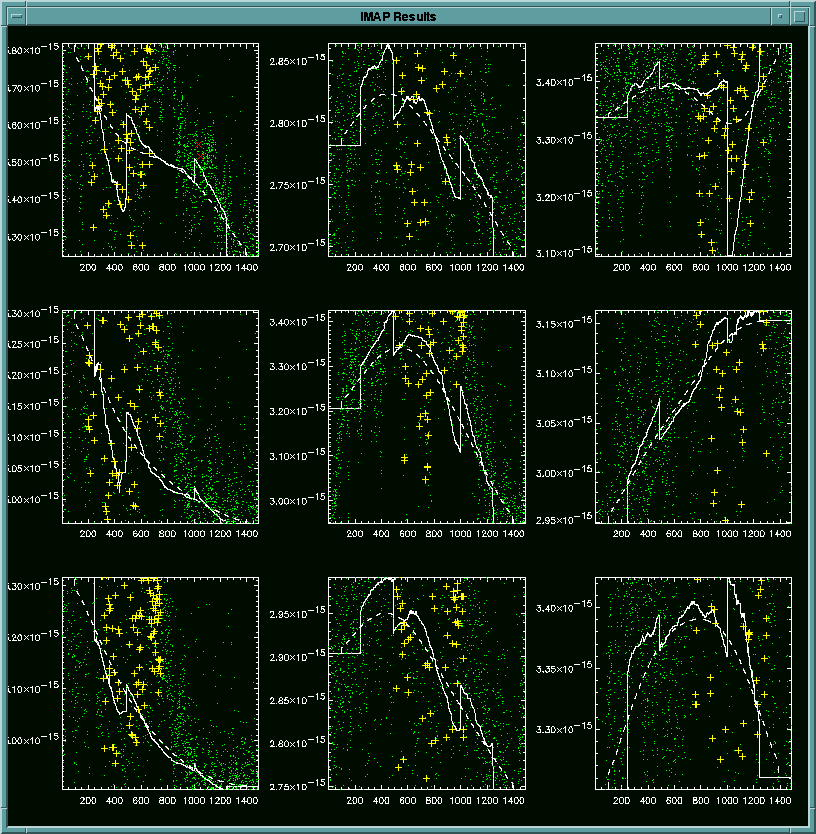
An IDL display window designed to fit four plots appears. The two
plots on the left are surface plots of the mean values of all the cells,
and each of the two plots on the right shows the view of the corresponding
surface plot to its left as seen from the point directly above it with
overplots of contours and dots which represent the centers of each pixel
at each chopper plateau. The X in the lower right plot will show
all the flagged points. If there is no X present in the lower right
plot, then the two surface plots on the left are exactly the same except
for the scale along the z-direction. This display is saved into a
postscript file named imap_result.ps.
DISPLAY
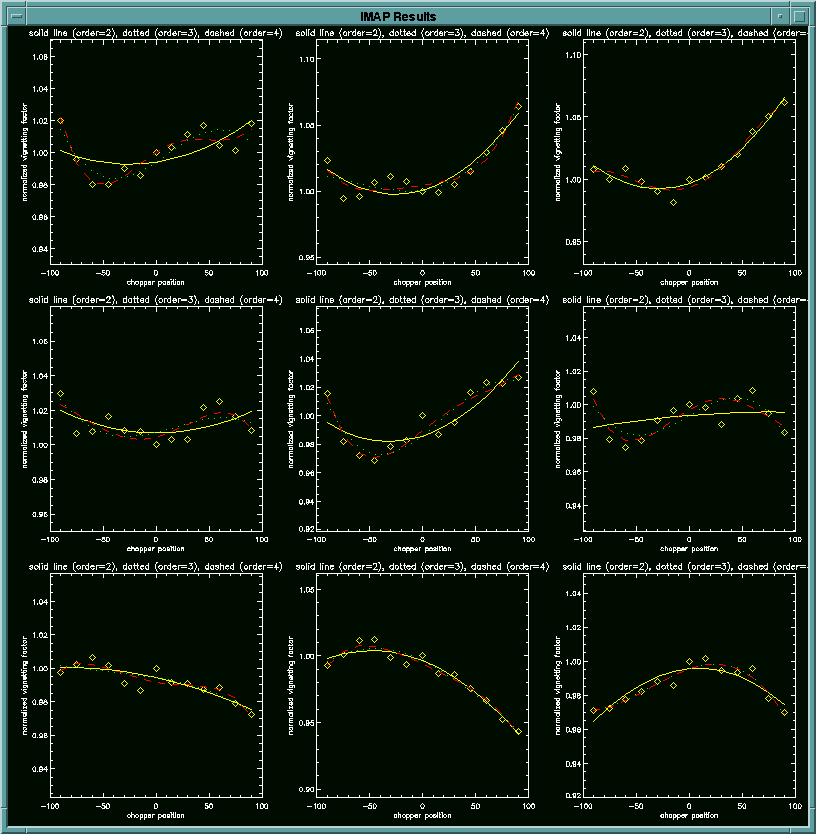
For each pixel, its CPVIGN is fitted with polynomials of order 2, 3 and
4 which are plotted as yellow solid line, green dotted line, and red dashed
line respectively. Please refer to the following setup for the pixel
arrangement on the IDL display window.
| pixel #1 | pixel #2 | pixel #3 |
| pixel #4 | pixel #5 | pixel #6 |
| pixel #7 | pixel #8 | pixel #9 |
| pixel #1 | pixel #2 |
| pixel #3 | pixel #4 |
DISPLAY
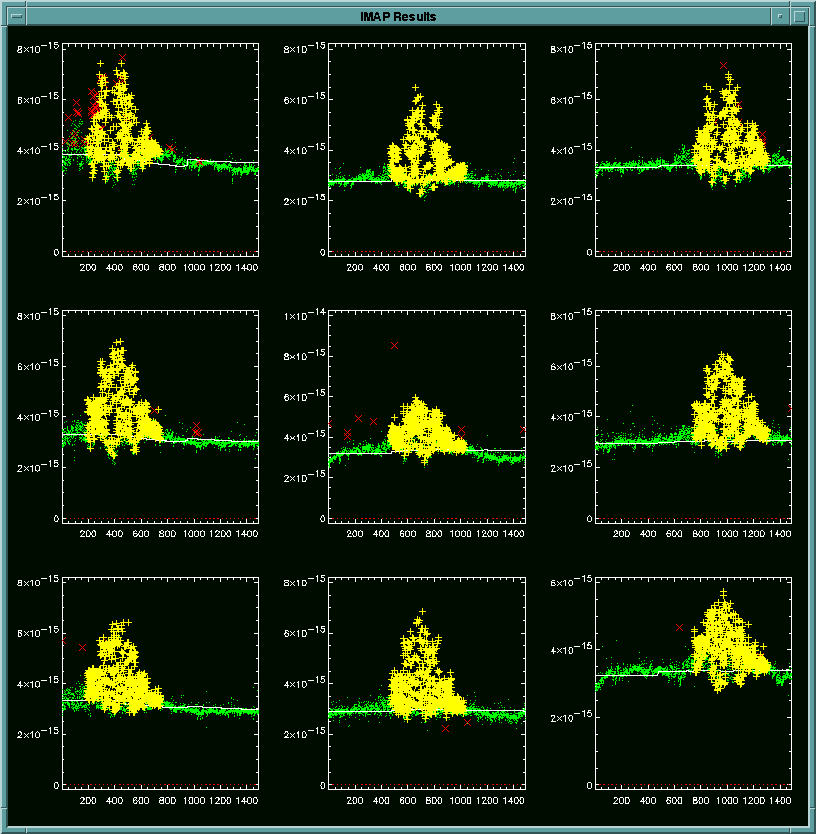
For each pixel, the data points are plotted along with the moving median
just calculated. The x-axis is the time in seconds, and the y-axis
is the signal in watts. The green dots represent the data points
with FLAG = 0 and 1, yellow plus signs show the masked out bright
signals, red dots denote the data points with FLAG = 2, red Xs depict the
flagged points using the cells, and finally the white line is the calculated
moving median. This result is also saved to the postscript file,
imap_result.ps. In the postscript file, different symbols are used
to distinguish between different data points instead of colors as in the
actual window display.
DISPLAY
If the answer to any of the above two questions is yes, then the zoomed
in plots show up. All the conventions are the same as before, but
now the smoothed curves will be overplotted.
DISPLAY
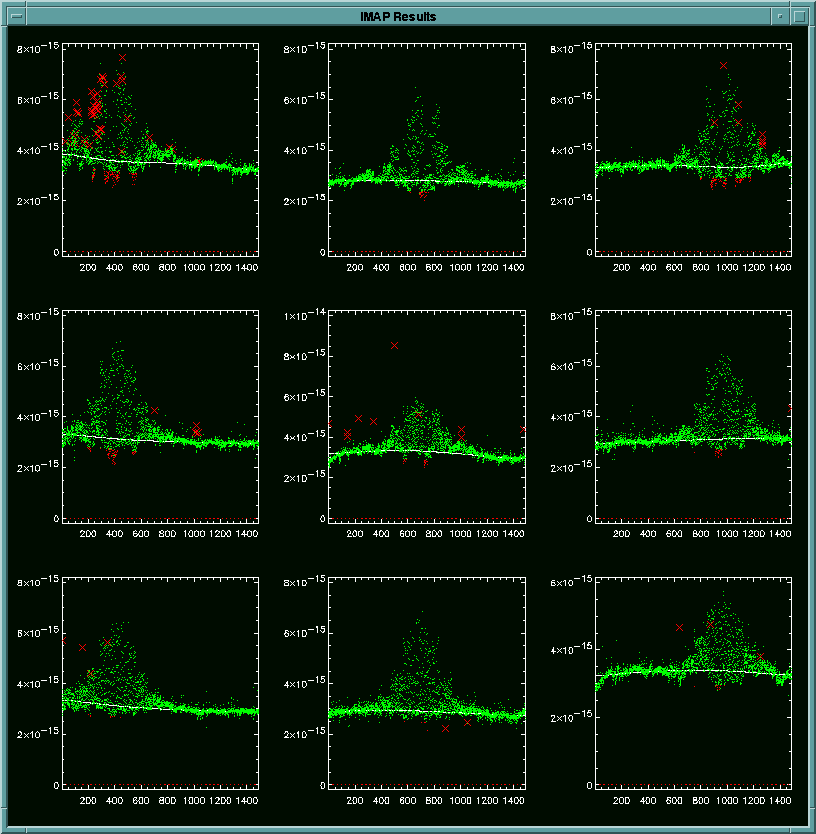
The result of this clipping under the bright source is displayed.
The green dots show all the good data points, the red Xs represent the
flagged points from the cleaning with cells, and the red dots show the
flagged points whose signals are below the moving median by more than the
user-defined number of sigmas. This result is saved to the imap_result.ps
file. In this postscript result, only the data points with FLAG =
0 and the moving median curves are displayed to avoid clutter.
DISPLAY
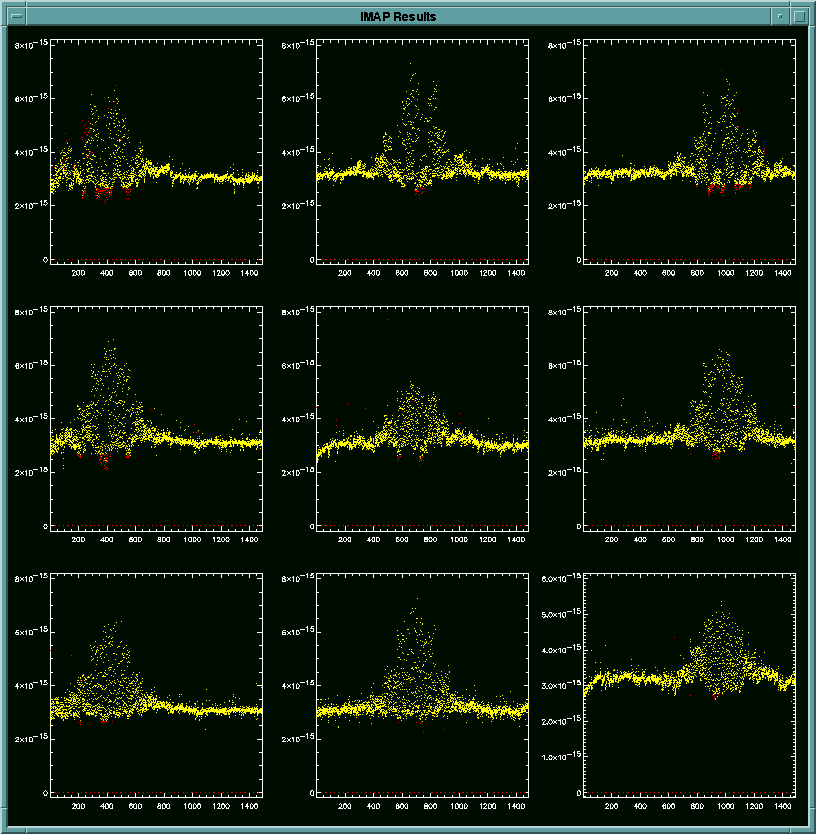
The final result is plotted on two different display windows. The
first one shows the individual pixel data with time in seconds as the x-axis
and the signal in watts as the y-axis. The yellow dots represent
the valid data points, and the red dots show all the flagged points.
DISPLAY
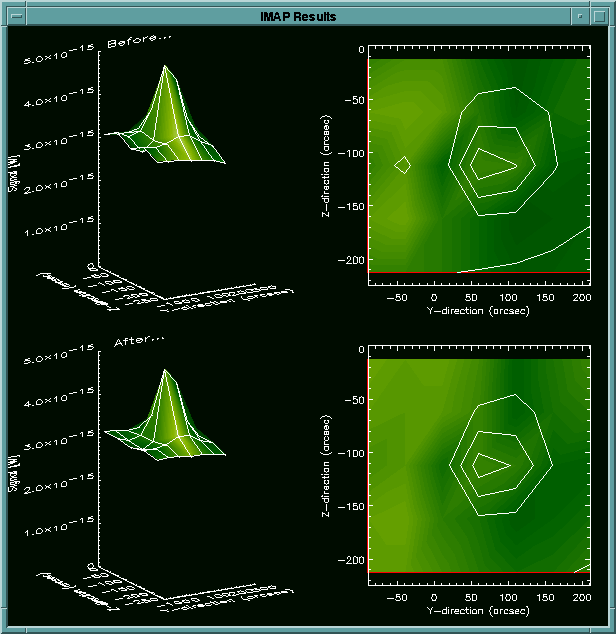
On the second display window, 3D surface plots are displayed (These are
very much like the ones shown before when masking bright sources).
On the top, it shows the data as before any of it changed from this
program, and the final resulting data is plotted on the bottom. These
two displays are also saved to the imap_result.ps file.
Nanyao Y. Lu
lu@ipac.caltech.edu
(626) 397-9505Min Y. Hur
hur@ipac.caltech.edu
(626) 397-7045

Mail Stop 100-22
770 S. Wilson Avenue
Pasadena, CA 91125
Fax : (626) 397-7018
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}