4. Star – Galaxy Discrimination
The ability to separate real extended sources (e.g., galaxies, nebulae, H II regions, etc) from stars is what fundamentally limits the reliability of any extended source catalog. Single isolated point sources represent the purest construct at which extended sources are compared and separated. More complicated constructs include ‘double’ stars and ‘triple+’ stars, these are generic labels that include both physically-associated multiple systems and chance superposition of stars on the sky. The permutations and combinations of multiple-star characteristics (radial separation, flux difference, color difference, etc) make them a challenge separate from real galaxies. What is more, since stars greatly outnumber extended sources by ~10:1 in most of the sky and by >100:1 in the galactic plane (cf. Fig. 12), for resolved galaxy in the sky there are many double+ stars that pose as extended source candidates.
There are many competing methods separating stars from galaxies, from the simplest "CART" methods (i.e., linearly measuring one attribute versus another), to the more sophisticated Bayesian-based methods (e.g., FOCAS; see Valdes 1982), decision trees (cf. Weir, Fayyad & Djorgovski, 1995) and neural networks (cf. Odewahn et al, 1992). Each method evolved and designed in response to increasingly more complicated data sets. For 2MASS, we were faced with the rather unique combination of near-infrared imaging and under-sampled data (2" pixels with a PSF that is quasi-stable) that called for yet another approach to star-galaxy discrimination to satisfy the rigorous level-1 specifications. Early experimentation with existing algorithms (e.g., FOCAS) were unsatisfactory primarily due to the severely undersampled 2MASS PSF, which changes width (and symmetry) over real time scales of minutes. Accordingly, the bulk of the 2MASS extended source processor, GALWORKS, is dedicated to the multi-layered task of star-galaxy separation. The basic approach is for GALWORKS to accurately measure and track the time-varying PSF and compare it with several different object attributes (i.e., parameterization) by applying some simple CART-like rules to cull out most of the multiple stars and artifacts that mimic real extended sources. The resultant extended source database is approximately 80% reliable for most of the sky. In a post-processing phase, further refinements, including more complicated attribute combinations and decisions trees, are used to produce the extended source catalog at a reliability of greater than 98% for K < 13.5. Below we describe and discuss some of the more critical parametric measurements and decision tree operations utilized to that end.
4.1 Stellar Ridgelines and Basic Object Characteristics
Resolved sources are initially identified by comparing their radial profiles with that of the nominal point spread function. As is the case for all ground based observations, the PSF changes with time due to the changing thermal environment and dynamic atmospheric "seeing" (see section 2.4); additionally, the PSF has an intrinsic spread caused by the pixel undersampling and dither pattern. Both effects are measured and tracked using our generalized exponential function (see also Eq. 1), and stellar ridge profiles (Fig. 2). The radial "shape" (a ´ b), or simply "sh", of a source is compared to the stellar ridge value, sh0, and a N-sigma "score" is computed as:
![]()
where sh0(t¢ ) and Dsh0(t¢ ) denote the time variable ridgeline value and its associated uncertainty and sh(t) the source value, with time t¢ as close to real t as possible. The PSF ridgeline value is stable over all flux levels, so only one value is needed per time interval. The "sh" uncertainty includes both measurement error and the intrinsic PSF spread. However, since SNR > 10 stars are plentiful in most areas, the measurement error is minimal compared to the real spread in the PSF. The uncertainty represents the RMS in the "sh" distribution, but the distribution has triangular-shaped wings (i.e., the scatter in "sh" falls of linearly). Consequently, stars will not have "sh" values above a threshold of ~2*Dsh0, but galaxies and other relatively ‘extended’ objects (e.g., double stars) will have scores >2. In Figure 11 we display the J-band "shape" scores of three kinds of objects that 2MASS commonly encounters: stars, multiple stars (double stars and triple+ stars), and galaxies. Stars occupy a locus about zero "sh" score (essentially defining the ridgeline), while multiple stars lie well above the ridgeline along with galaxies and other "fuzzy" sources. Note that the number of stars display has been reduced by a factor of 10 relative to the other plots. The "sh" score is very effective at separating isolated stars from galaxies at flux levels as faint as ~15.4 in J band.
Other GALWORKS-derived image parameters that are effective at separating isolated stars from galaxies include the 1st and 2nd intensity-weighted moments, ratio of the central surface brightness to the integrated brightness, and areal measures (e.g., isophotal area). Unfortunately, like the radial "sh" parameter, none of these diagnostics can galaxies from sky-projected star clusters to the degree necessary to meet the level-1 specifications. Double stars are in particular a vexing component due to their sheer numbers at galactic latitudes < 20° . Figure 12 shows the expected number of double stars and triple stars as a function of Galactic latitude (at longitude 90° ) for K < 13.5. Sky-projected doubles contribute less than ~2% of the total at high galactic latitudes, but quickly begin to dominate the total numbers for latitudes less than 5 degrees. Even at moderate stellar number density, double stars are comparable in number to galaxies for typical 2MASS flux levels. We clearly see that double stars (and triple+ stars near the galactic plane) are the primary contaminant of the galaxy database. More intricate attributes are needed to exploit the differences between groupings of point sources and real fuzzy objects (resolved galaxies).
4.2 Multiple Star – Galaxy Separation using Symmetry Metrics
In the near-infrared, galaxy morphology usually show smooth radial and azimuthal profiles. Spiral galaxies have much more light distributions in the near-infrared than optical because the emission is dominated older stellar populations, including low mass dwarfs and red giants, which are spread more throughout the disk, and the absorption is greatly reduced. Large-scale features commonly seen in the radio and optical wavelengths, including H II regions, supernova remnants and dust lanes, are generally difficult to detect in the near-infrared except in the nearest galaxies; Figure 13a shows some large angular scale galaxies located in the Virgo cluster. Only the relatively rare cases of galaxies subject to strong tidal or hydrodynamical interaction exhibit significant asymmetry in the near-infrared bands. In contrast, multiple stars, and in particular double stars, are not symmetric about their ‘primary’ center. Here the center of a multiple star corresponds to the brightest member in the group, or more specifically, the peak pixel associated with the brightest star. The near-infrared symmetry of galaxies can be exploited to differentiate between multiple stars that otherwise mimic extended sources.
Figure 13b illustrates a variety of double stars seen in 2MASS images. For comparison, a set of galaxies of approximately the same integrated brightness as that of the double stars is also shown in the lower panel. For double stars, the "secondary" component of the system is what breaks the symmetry of the primary, which otherwise would have the symmetric shape of the PSF. One of the obvious symmetry attributes is to ratio the integrated flux as measured on one side of the primary and on the opposite side (containing the secondary star). The system is defined as an ellipse with the primary at the center and the secondary along the major axis.
A different tact is to ‘remove’ the secondary and measure the resultant "sh" of the primary. We are of course faced with the problematic fact that the emission from both sources are entangled and the primary itself has changed both its radial ("sh") width and its azimuthal (symmetry) shape. If the PSFs were exceptionally stable and well characterized as such, then in principle it would be possible to satisfactorily de-blend the multiple sources into their constituent parts. Since this condition is never realized, and moreover the runtime for this kind of PSF c
2 fitting is prohibitively long, we are left with the only option of bluntly removing the secondary. The simplest approach is to remove the secondary using a median filter in annular shells about the primary: GALWORKS refers to the resultant measure as the "median shape" or just "msh". Another more complicated approach is to mask the secondary and measure the residual emission from the primary, using a wedge or pie-shaped mask that is rotated about the vertex which is anchored to the primary. The optimum configuration in which the secondary is effectively masked is found by rotating the wedge mask through all angles (Figure 14; also illustration below for your convenience). 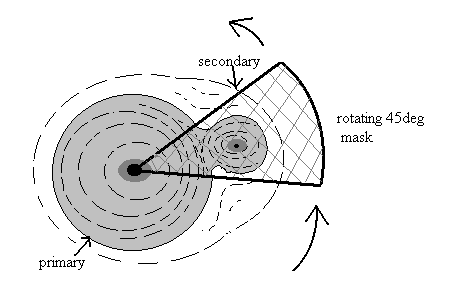
The "sh" score is then computed for the remaining (360° – 45° ) pixels. If the secondary star is masked, then the resultant "sh" score will be minimized, ideally with a value corresponding to an isolated star. In practice the secondary can never be fully masked, and the peak pixel does not represent the true center of the primary since it is slightly shifted toward the secondary – thus resulting in an artificially inflated "sh" score relative that of an isolated star. Nevertheless, the "wedge" shape score, or simply "wsh", is an effective discriminant. This is as demonstrated in Figure 15, which is analogous to Figure 11; here we show the distribution of multiple stars and galaxies as measured in the "wsh" versus magnitude plane.
The wedge shape score for double stars is considerably smaller than the corresponding "sh" score, having values typically less than 5 for J < 15, while galaxies remain "extended" in this measure with scores >5 for J < 15. Note however, triples+ stars are only occasionally identified as such by the "wsh" score since the additional two secondary components usually defeats the single rotating mask method. For triple stars, yet more severe "symmetry" constraints are required.
Triple stars are geometrically more difficult to characterize because of the number of possible combinations of integrated flux and primary-secondary separations. The "Achilles' heel" of most triple stars is that along some vector (anchored to the primary) there is minimal contamination from the two secondary components. If we measure the radial "sh" of this vector and compare it to the corresponding ridgeline value, the resultant ‘score’ should be close to that of an isolated star. Thus the basic method is to measure the "sh" along an azimuthally distributed set of vectors (angular separation 5° ). Departure of this "sh" value from that of the ideal case of an isolated star is principally contamination from the secondary(s) shift the primary peak pixel and drive flux into the radial/azimuthal profile of the primary. The vector corresponding to the ‘minimum’ shape score (referred to as the "R1" score) is susceptible to background noise fluctuations since we are restricting the (a,b) fitting operation to less than a dozen pixels. For galaxies, the "r1" score tends to select against galaxies that are edge-on and thus have minimal (but still measurable) extended emission along the minor axis (i.e., the vector corresponding to the minimum radial "sh" score).
A more robust parameter (but slightly less effective at removing the influence of the secondary components) is to average the 2nd and 3rd lowest "sh" value vectors (that is, avoid the "r1" vector). This score is referred to as the "r23" shape score. Here we are relying upon the fact that most triple star configurations (but not all by any means) will have more than one vector that is minimally affected by the secondary components. Galaxies, meanwhile, are generally extended in all directions and so the "r23" score is not much different from the "sh" score except for the faintest galaxies (J > 15, K > 13.75) which are at the mercy of noise fluctuations.
The effectiveness of the "r23" score is demonstrated in Figure 16. Here we plot the "r23" versus magnitude phase space. It can be seen that the triple stars are now well under control with minimal loss to the galaxies at J < 14, while for the faint mag bins, J > 14, galaxies are not well separated from triple stars. But, as it turns out, triple stars are only abundant when the stellar number density is very high (i.e., the galactic plane; see Fig. 12), which means that the ‘confusion’ noise is also high (that is, the random fluctuations in the background due to faint stars) , rendering the sensitivity limits for galaxy detection itself from 0.5 to nearly 2 mags brighter than the high-latitude 2MASS limits. Thus, just as the problem with triple stars becomes significant, the practical detection thresholds are correspondingly decreased, thereby leaving the "r23" score as an effective star-galaxy discriminator for flux levels up to the detection limits. For the most extreme stellar number density cases (e.g., regions of Baade’s windows), >105 stars per deg2 brighter than 14th at K, quadruple ++ stars become significant, at which point there is no way to separate galaxies from clusters of stars.
We have developed additional parameters designed to minimize contamination from triple stars, including flux gradients along radial vectors (referred to as the "vgrad" score) and integrated flux along radial ‘column’ vectors (referred to as the "vint" score). Similar to the "r1" and "r23" scores, these methods rely upon the ‘minimum’ column integrated flux or gradient in the column flux to be similar to that of isolated stars. They are not quite as effective as the "sh" vector scores, but since they are only slightly correlated, they can be used in combination with the other attributes when using a decision tree.
4.3 The Color Attribute
Two effects conspire to make galaxies appear "red" in the 1-2 mm window: their light is dominated by older and redder stellar populations (e.g., K and M giants), and their redshift tends to transfer additional stellar light into the 2 mm window (for z < 0.5), boosting the K-band flux relative to the J-band flux. The latter phenomenon is rectified with what is known as a "K correction", or a model-dependent flux correction to the observed colors. Because of this, the J-K color attribute can be used – in conjunction with color-independent discriminants, like the "wsh" score -- to cleanly separate extragalactic objects from stars. As a bonus, the color separation is enhanced in the galactic plane where double and triple star contamination is severe. This is because galaxies are subject to a larger column dust compared to random field stars along the same line of sight. We demonstrate the effectiveness of the J-K color to separate stars from resolved galaxies in a diverse set of fields, including areas well above the galactic plane, referred to as low stellar density fields (<103.1 stars per deg2 brighter than 14th at K), and areas closer to the plane (glat > 5 degrees) , referred to as moderate density fields ( <103.6 stars per deg2), and finally areas in the galactic plane in which the stellar number density is very high (>103.6 stars per deg2 brighter than 14th at K). For the latter case, the confusion noise is typically very high (>1 mag) so the sensitivity limits have been decreased accordingly.
The J-K color for galaxies and double stars located in low density areas is shown in Figure 17 with three different integrated flux ranges. Here we ignore the contribution of triple stars to the total mix (since their numbers are insignificant in these areas). Figures 18 shows the color distribution for sources located in moderate density fields, and Figure 19 sources from high density fields.
A J-K color of ~1.0 appears to be a reasonable compromise for separating stars from galaxies. For flux levels relevant to the 2MASS level-specifications, K < 13.5, a J-K color limit of 1.0 eliminates nearly all (>95%) double stars that mimic galaxies, while more than 90% of the total galaxy distribution has a color greater than this limit. The same trend is observed in the more confused regions of the sky (Figure 18 & 19) where star-galaxy discrimination is at a premium. Another way to view the color separation between stars and galaxies is within the J-H vs. H-K color plane, Figures 20-22. Here we include the stellar main sequence track, showing the divergence of giants from dwarfs at H-K > 0.3. In addition, we note the K-correction track for spiral galaxies derived from the models of Bruzual & Charlot (1993).
At fainter flux levels, K > 13.5, the scatter in the integrated flux (and thus colors) is large enough that false galaxies (i.e., double and triple stars) can scatter above the J-K color limit and galaxies can have colors that scatter below the limit to a degree that contamination and completeness is significantly compromised if the J-K attribute were used as the lone discriminant. Moreover, for all flux levels, a J-K threshold would impart an undesirable selection bias against blue galaxies. To minimize color biases, the J-K attribute can be combined with the radial shape attributes (e.g., the "wsh" score) to form a new powerful discriminant. First, the color-color plots suggest a more optimum method to use JHK colors to measure the "redness" of a galaxy. Galaxies are not only preferentially redder than 0.9 in J-K, but they also have H-K values, >0.2, redder than most stars. Hence, we define a "color score" as the color distance in J-H vs. H-K space from the line corresponding to J-K = 0.9 to within a scaling factor. For objects redder than 0.3 in H-K, we also factor in the H-K color to exploit this feature in the JHK color space. Mathematically, we express the "color score" as:
![]()
which adds the color ‘distance’ (to within a scaling factor) from the dotted line in Figure 20. For sources with (H-K)>0.3, the color score reduces to:
![]()
The color score can be directly combined with one of the color-independent attributes (e.g., "wsh") to provide additional star-galaxy separation. Figure 23 demonstrates the combination of color score and "wsh". This combination parameter alone is capable of providing better than 95% reliability (K < 13.5) with only a few % loss of galaxies to the total population. We can do better still by using all of the attributes with a decision tree classifier.
4.4 Oblique Decision Tree Classifier
Three classes of attributes have been introduced thus far: radial extent or shape ("sh", "r1", "r23"), symmetry or azimuthal shape ("wsh", "msh", flux ratio) and flux or photo-metrics ("vint", "color score", total flux, and central surface brightness relative to the total flux). We have something like a nine-dimensional space to probe (per band) for any given source to decide if it is extended. To complicate matters, several of the attributes are highly correlated (e.g., "wsh" and "msh") and others weakly correlated (e.g., "wsh" and the bi-symmetric flux ratio), which ultimately prevents simple or weighted combination of the attributes to form a "super" attribute. We may either combine a few of the attributes that are not correlated (e.g., color score and "wsh" and "r23"), cf. Figure 23, or employ a decision tree induction method (cf. Breiman et al. 1984) to effectively combine all of the attributes. In the last few years, decision trees and their close cousins, machine-learning artificial neural networks, have been used by astronomers to aide in image classification (e.g., Weir et al, 1995; Odewahn et al. 1992; White 199?; Salzberg et al. 1995). With fast computer technology these methods provide an efficient means to analyze multi-dimensional data. We will consider one particular type of decision tree, called the oblique-axis decision tree, but there are many others that should be effective. Neural nets also have been shown to be very useful for classification, but given their complexity and non-intuitive nature, we will not consider them at this time.
Decision tree methods, like artificial "neural networks", require a ‘training’ set of pre-classified (reliable) data composed of all combinations of stars (isolated, double, triple, etc) and galaxies. This "truth" set is used to generate the decision tree, or a structured set of classification rules. Using the analogy of a tree, the rule structure contains ‘nodes’ of branching test points with the final nodes in the tree representing the ‘leaves’ or final classification. For example, one node might represent a test of the "wsh" score, comparing the score to some threshold, T,
"wsh" score > T ?
NO: classify as non-galaxy
YES: continue to next node
This is an example of an "axis-parallel" decision. That is to say, the parameter or object attribute embodies a set of hyperplanes (in the multi-dimension phase space) that are parallel to each other. Figure 24 demonstrates a two-featured, hyperplane: "wsh" score vs. J mag with galaxies denoted by filled circles and non-galaxies by crosses. The non-galaxies are mostly double stars in this example. The dashed parallel lines represent the axis-parallel "rules". To the right (or above) of the lines are the galaxies, to the left (and/or below) the lines are the false galaxies or non-galaxies. Axis-parallel rules have the advantage of being simple to apply and track within a large complicated tree. But it is obvious from the example plot that a better rule is to use an "oblique" line separating the two populations or features. The solid line in Figure 24 is an example of an oblique-axis ruling. An oblique decision tree uses both axis-parallel and oblique-axis tests at the nodes. Mathematically, the node test has the form:
![]()
where object O possesses n attributes, with a coefficients or weights defining the n-dimensional hyperplane. For the reduced axis-parallel case, the linear sum reduces to ajOj > T. Although oblique hyperplanes are just a series of linear combinations, the total possible number of solutions is very high and thus finding the ‘correct’ one is daunting, if not impossible under some conditions. In fact, the problem is NP-Complete, or ultimately limited by the runtime of the machine. Fortunately, in practice reasonable decision trees can be generated with clever deduction algorithms and techniques to avoid "traps" or local minimum solutions. One such package was developed by Murthy et al. (1994) called OC1, or Oblique Classifier 1. OC1 uses random perturbations to walk around traps and arrive at proper (or more likely, satisfactory) hyperplane solutions for each node. The resultant tree may require ‘pruning’ or stripping of branches that add little to the final classification, or worse, detract from the correct solution due to over-fitting of the training set (which is ultimately finite and limited). OC1 applies pruning methods, e.g., Cost Complexity pruning (cf. Breiman et al 1984), which effectively prunes the decision tree by removing the insignificant or "weak" branches. For the problem of over-fitting, in addition to pruning, the best solution is to minimize the total number of attributes per node. For 2MASS galaxies, nine attributes including the integrated flux characterize each source. The attributes are correlated to one degree or another, so it is not obvious which attribute(s) can be eliminated from the decision tree process. Experimentation with the training sets and additional pre-classified data sets give us the only clue as to the level of pruning that our decision tree requires. One disadvantage that decision trees have with classification of galaxies is that the final classification does not have an associated uncertainty or probability of being a galaxy. A probability is what is really needed, so the designers of decision tree algorithms have made this one of their priorities for future design. For 2MASS galaxies, we can "assign" a probability by using a weighted average of the decision tree classifications for each band (details given below).
The 2MASS star-galaxy separation problem is ideally suited to an oblique decision tree technique. Accordingly, we have applied the OC1 technique to large data (training) sets of 2MASS extended sources and non-galaxies (stars, double stars, triples, etc). The sets are delineated into three subsets, one for low stellar density fields, <103.1 stars per deg2 brighter than 14th at K, one for density fields, 103.1 to 103.6 stars per deg2, and one for high density fields,>103.6 stars per deg2 brighter than 14th at K. The subsets are further divided into three or four sub-subsets depending in the integrated flux of the source. The latter step minimizes the severe dynamic range (in flux) that 2MASS must consider, from the brightest galaxies (K < 9) to the faintest galaxies (K > 14). The training sets are large and diverse (the low-density set contains over 15000 objects, over some 280 sq. degrees) and thus provide a suitable induction test bed for the decision tree algorithm. Preliminary results show that with the OC1 decision tree classifier the galaxy catalog reliability increases several percent compared to just using simple CART or axis-parallel tests. The trend persists in regions of high stellar number density where double and triple stars become a major contaminant. More detailed results of the completeness and reliability are given in section 6. Future work to refine the decision trees will focus upon further pruning of the trees and upon possible elimination of "weak" and highly correlated attributes. It may also prove fruitful to evaluate other decision tree methods (for example those developed by Weir et al. 1995; Fayyad 1994) and, possibly, artificial neural network methods, particularly if morphological classification is attempted (i.e., construing the galaxy type and sub-types) with 2MASS imaging data.