4.4 Oblique Decision Tree Classifier
Three classes of attributes have been introduced thus far: radial extent or shape ("sh", "r1", "r23"), symmetry or azimuthal shape ("wsh", "msh", flux ratio) and flux or photo-metrics ("vint", "color score", total flux, and central surface brightness relative to the total flux). We have something like a ninth dimensional space to probe (per band) for any given source to decide if it is extended. To complicate matters, several of the attributes are highly correlated (e.g., "wsh" and "msh") and others weakly correlated (e.g., "wsh" and the bi-symmetric flux ratio), which ultimately prevents simple or weighted combination of the attributes to form a "super" attribute. We may either combine a few of the attributes that are not correlated (e.g., color score and "wsh" and "r23"), see Figure 12, or employ a decision tree induction method (cf. Breiman et al. 1984) to effectively combine all of the attributes. In the last few years, decision trees and their close cousins, machine-learning artificial neural networks, have been used by astronomers to aide in image classification (e.g., Weir et al, 1995; Odewahn et al. 1992; White 199?; Salzberg et al. 1995). With fast computer technology these methods provide an efficient means to analyze multi-dimensional data. We will consider one particular type of decision tree, called the oblique-axis decision tree, but there are many others that should be effective. Neural nets also have been shown to be very useful for classification, but given their complexity and non-intuitive nature, we will not consider them at this time.
Decision tree methods, like artificial "neural networks", require a ætrainingÆ set of pre-classified (reliable) data composed of all combinations of stars (isolated, double, triple, etc) and galaxies. This "truth" set is used to generate the decision tree, or a structured set of classification rules. Using the analogy of a tree, the rule structure contains ænodesÆ of branching test points with the final nodes in the tree representing the æleavesÆ or final classification. For example, one node might represent a test of the "wsh" score, comparing the score to some threshold, T,
"wsh" score > T ?
NO: classify as non-galaxy
YES: continue to next node
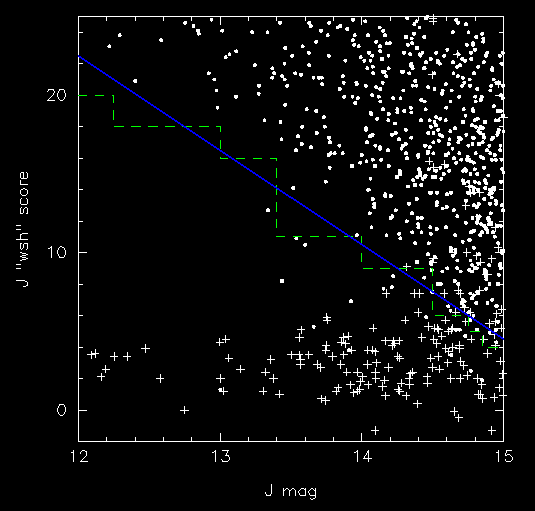
This is an example of an "axis-parallel" decision. That is to say, the parameter or object attribute is embodies a set of hyperplanes (re: multi-dimension phase space) that are parallel to each other. Figure 13 demonstrates a two-featured, hyperplane: "wsh" score vs. J mag. The features correspond to what is relevant to the 2MASS project: galaxies (denoted by filled circles) and non-galaxies (crosses). The non-galaxies are mostly double stars in this example. The dashed parallel lines represent the axis-parallel "rules". To the right (or above) of the lines are the galaxies, to the left (or below0 the lines are the false galaxies or non-galaxies. Axis-parallel rules have the advantage of being simple to apply and track within a large complicated tree. But it is obvious from the example plot that a better rule is to use an "oblique" line separating the two populations or features. The solid line in Figure 13 is an example of an oblique-axis ruling. An oblique decision tree uses both axis-parallel and oblique-axis tests at the nodes. Mathematically, the node test has the form:
![]()
where object O possesses n attributes, with a coefficients or weights defining the n-dimensional hyperplane. For the reduced axis-parallel case, the linear sum reduces to ajOj > T. Although oblique hyperplanes are just a series of linear combinations, the total possible number of solutions is very high and thus finding the æcorrectÆ is daunting, if not impossible under all conditions. In fact, the problem is NP-Complete, or ultimately limited by the runtime of the machine. Fortunately, in practice reasonable decision trees can be generated with clever deduction algorithms and techniques to avoid "traps" or local minimum solutions. One such package was developed by Murthy et al. (1994) called OC1, or Oblique Classifier 1. OC1 uses random perturbations to walk around traps and arrive at proper (or more likely, satisfactory) hyperplane solutions for each node. The resultant tree may require æpruningÆ or stripping of branches that add little to the final classification, or worse, detract from the correct solution due to over-fitting of the training set (which is ultimately finite and limited). OC1 applies pruning methods, e.g., Cost Complexity pruning (cf. Breiman et al 1984), which effectively prunes the decision tree by removing the insignificant or "weak" branches. For the problem of over-fitting, in addition to pruning, the best solution is to minimize the total number of attributes per node. For 2MASS galaxies, nine attributes including the integrated flux characterize each source. The attributes are correlated to one degree or another, so it is not obvious which attribute(s) can be eliminated from the decision tree process. Experimentation with the training sets and additional pre-classified data sets give us the only clue as to the level of pruning that our decision tree requires. One disadvantage that decision trees have with classification of galaxies is that the final classification does not have an associated uncertainty or probability of being a galaxy. A probability is what is really needed, so the designers of decision tree algorithms have made this one of their priorities for future design. For 2MASS galaxies, we can "assign" a probability by using a weighted average of the decision tree classifications for each band (details given below).
The 2MASS star-galaxy separation problem is ideally suited to an oblique decision tree technique. Accordingly, we have applied the OC1 technique to large data (training) sets of 2MASS extended sources and non-galaxies (stars, double stars, triples, etc). The sets are delineated into three subsets, one for low stellar density fields, <103.1 stars per deg2 brighter than 14th at K, one for density fields, 103.1 to 103.6 stars per deg2, and one for high density fields,>103.6 stars per deg2 brighter than 14th at K. The subsets are further divided into three or four sub-subsets depending in the integrated flux of the source. The latter step minimizes the severe dynamic range (in flux) that 2MASS must consider, from the brightest galaxies (K < 9) to the faintest galaxies (K > 14). The training sets are large and diverse (e.g., the low-density sets contains over 15000 objects, comprising some 280 sq. degrees) and thus provide a suitable induction test bed for the decision tree algorithm. Preliminary results show that with the OC1 decision tree classifier the galaxy catalog reliability increases several % compared to just using simple CART or axis-parallel tests. The trend persists in regions of high stellar number density where double and triple stars become a major contaminant. More detailed results of the completeness and reliability are given in section ??. Future work to refine the decision trees will focus upon further pruning of the trees and upon possible elimination of "weak" attributes. It may also prove fruitful to evaluate other decision tree methods (for example those developed by Weir et al. 1995; Fayyad 1994) and, possibly, artificial neural network methods, particularly if morphological classification is attempted (i.e., construing the galaxy type and sub-types) with 2MASS imaging data.
Figures
Figure 1-- Distribution of stars, multiple stars and galaxies in the J-band "sh" versus magnitude parameter plane. The sources do not come from the same sample; e.g., the triple stars are derived from high stellar source density fields in the galactic plane. Stars generally outnumber galaxies by a ratio of 10:1 for J brighter than 15th mag.
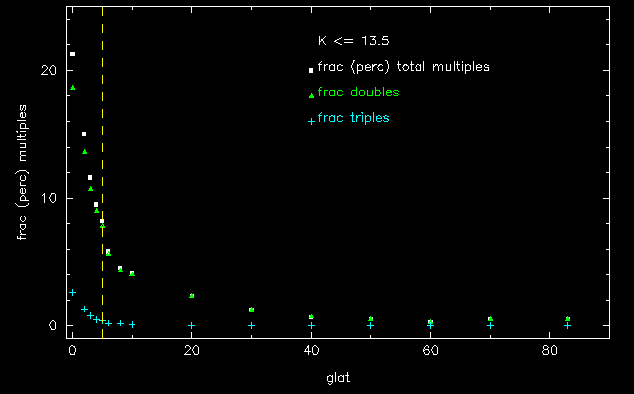
Figure 2-- The expected fractional percentage (of the total) of doubles stars (triangles) and triple stars (crosses) with galactic latitude. The longitude is fixed at 90 degrees. The calculations are based on the starcount models of Jarrett (1992). Double stars, dominated by sky-projected associations, represent æprimary-secondaryÆ separations of less than 6 arcsec (the 2MASS PSF for comparison has a FWHM > 2 arcsec).
Figure 3--Examples of 2MASS double stars and galaxies. The upper panels demonstrate various kinds of doubles encountered. The lower panels show galaxies with approximately the same flux as their double star counterparts (left most panel: J = 11th mag; right-most panel, J = 15th mag).
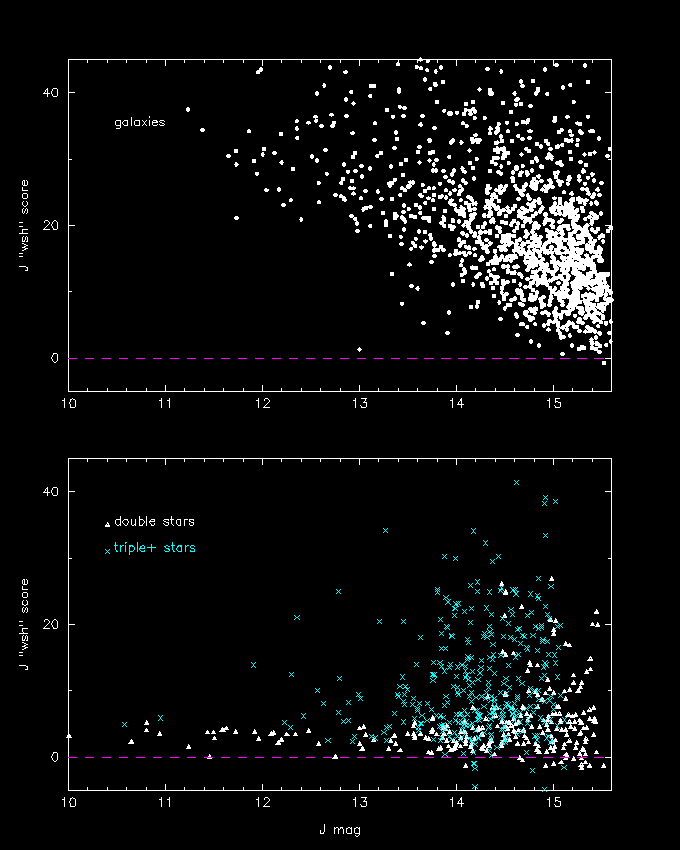
Figure 4-- Distribution of multiple stars and galaxies in the J-band "wsh" score versus magnitude parameter plane. The sources do not come from the same sample; e.g., the triple stars are derived from high stellar source density fields in the galactic plane
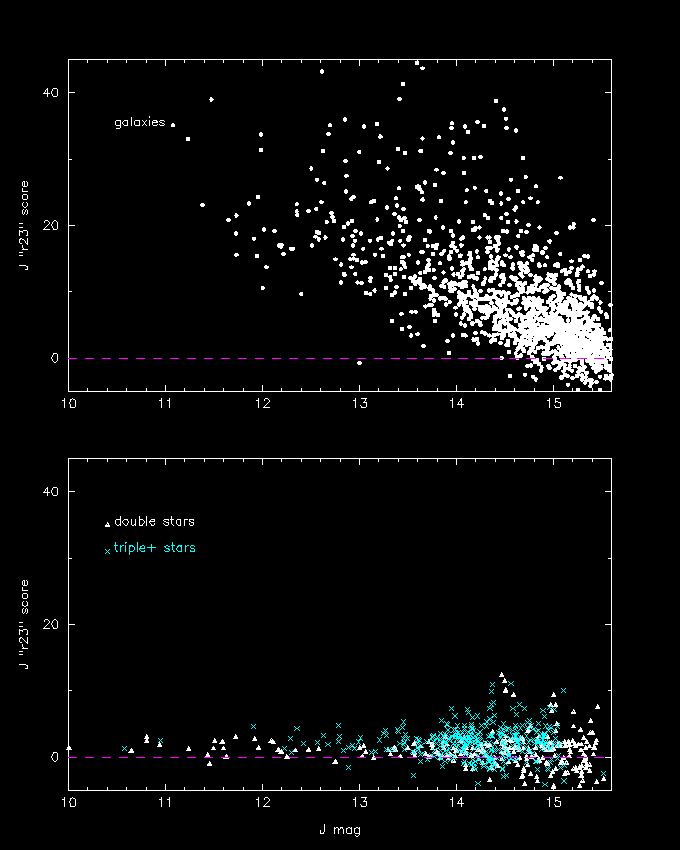
Figure 5-- Distribution of multiple stars and galaxies in the J-band "r23" score versus magnitude parameter plane. The sources do not come from the same sample; e.g., the triple stars are derived from high stellar source density fields in the galactic plane.
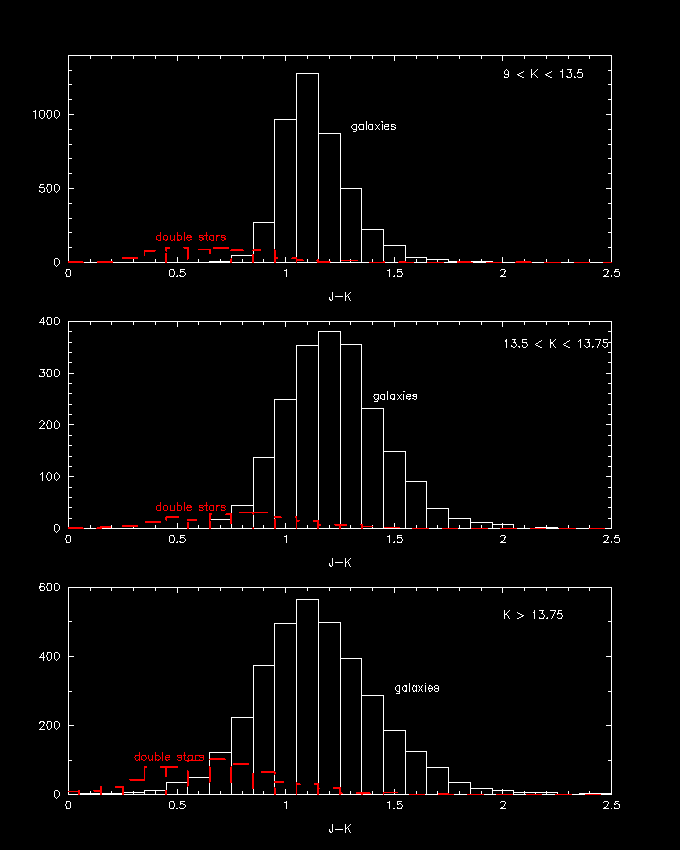
Figure 6ùHistogram of the J-K color distribution for galaxies and double stars. The upper panel is restricted to sources with K < 13.5. The middle panel represents sources at the sensitivity limit of the survey (K < 13.75) and the last panel shows sources generally fainter than the Kûband sensitivity limits (K > 13.75) but detected and extracted due in part to the superior sensitivity limit at J band. The data come from a diverse set of low stellar number density fields, comprising some 250 square degrees.
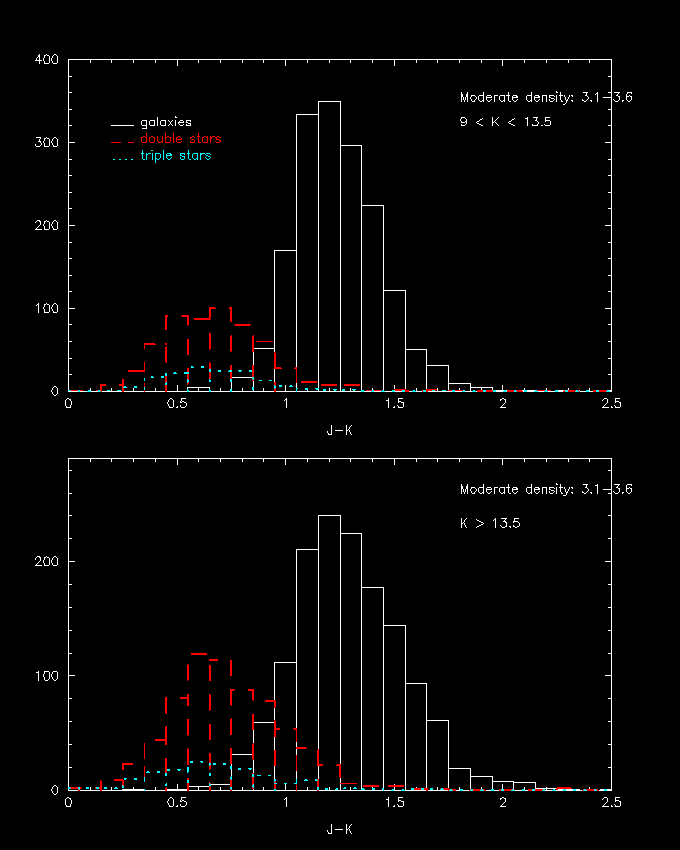
Figure 7-- Histogram of the J-K color distribution for galaxies and double stars in moderate stellar number density fields (103.1 û 10.3.6 stars/deg2). The upper panel is restricted to sources with K < 13.5, and the bottom panel K > 13.75. The data come from a diverse set of moderate stellar number density fields, comprising some 150 square degrees.
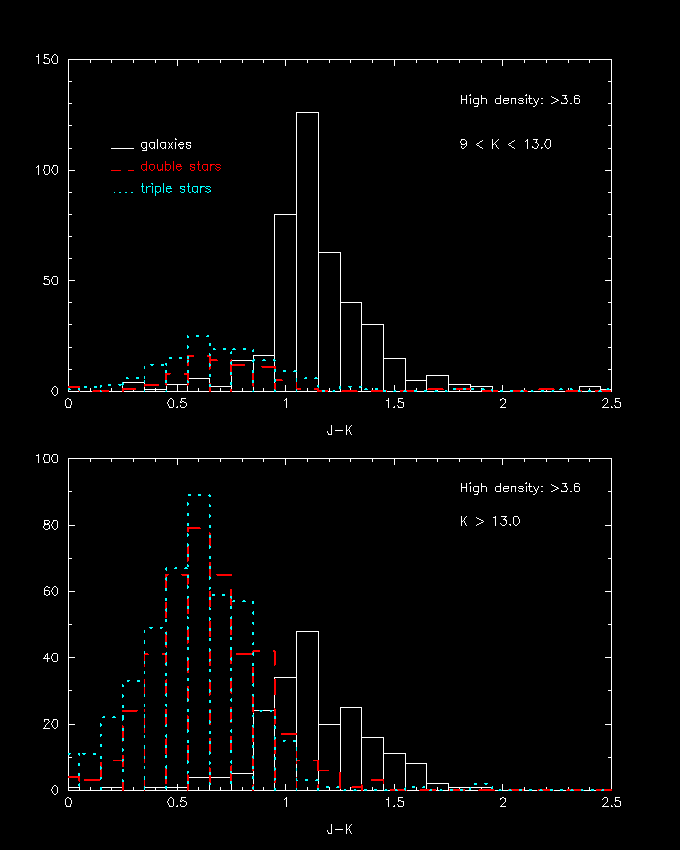
Figure 8-- Histogram of the J-K color distribution for galaxies and double stars in high stellar number density fields (>10.3.6 stars/deg2). The upper panel is restricted to sources with K < 13.0, and the bottom panel K > 13.0. The data come from a diverse set fields, comprising some 60 square degrees.
Figure 9--J-H vs. H-K color plane distribution for sources, K < 13.5, located in low stellar number density fields. Triangles denote double stars, crosses triple stars, and small points galaxies. The solid line demarks the main sequence tracks (dwarfs lower track, giants upper track). The K-correction track for spirals is shown with the dashed line. The large diamond symbols denote intervals of 0.1 in redshift (z).
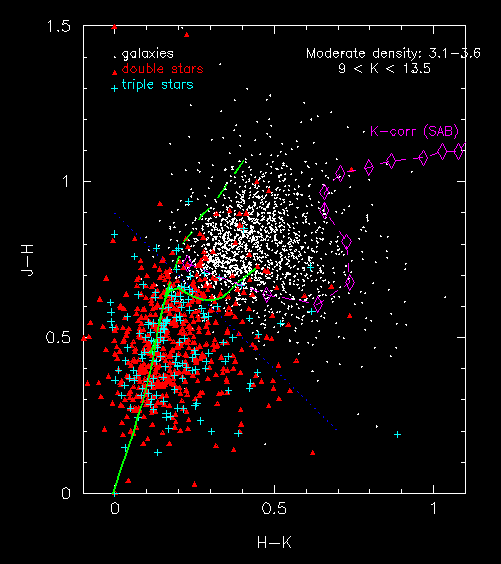
Figure 10-- J-H vs. H-K color plane distribution for sources, K < 13.5, located in moderate stellar number density fields. Triangles denote double stars, crosses triple stars, and small points galaxies. The solid line demarks the main sequence tracks (dwarfs lower track, giants upper track). The K-correction track for spirals is shown with the dashed line. The large diamond symbols denote intervals of 0.1 in redshift (z).
Figure 11-- J-H vs. H-K color plane distribution for sources, K < 13.0, located in high stellar number density fields. Triangles denote double stars, crosses triple stars, and small points galaxies. The solid line demarks the main sequence tracks (dwarfs lower track, giants upper track). The K-correction track for spirals is shown with the dashed line. The large diamond symbols denote intervals of 0.1 in redshift (z).
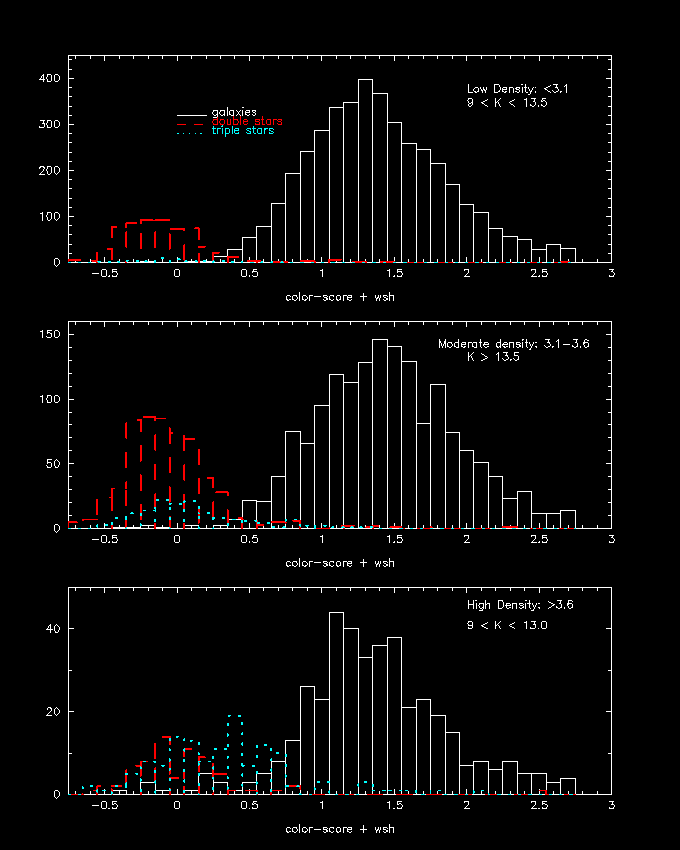
Figure 12--Distribution of stars and galaxies in the "color score + wsh" space. The upper panel corresponds to low stellar number density; middle panel to moderate stellar number density; lower panel to high stellar number density.
Figure 13ùAn example of a two-featured data hyperplane set that is addressed within a decision tree node. A subsection of the "wsh" score û J magnitude plane for galaxies (denoted with filled circles0 and non-galaxies (denoted with cross symbols) is shown (derived from sample shown in Figure 4). Axis-parallel planes are represented with dashed lines and the best-fit oblique plane in represented with a solid line.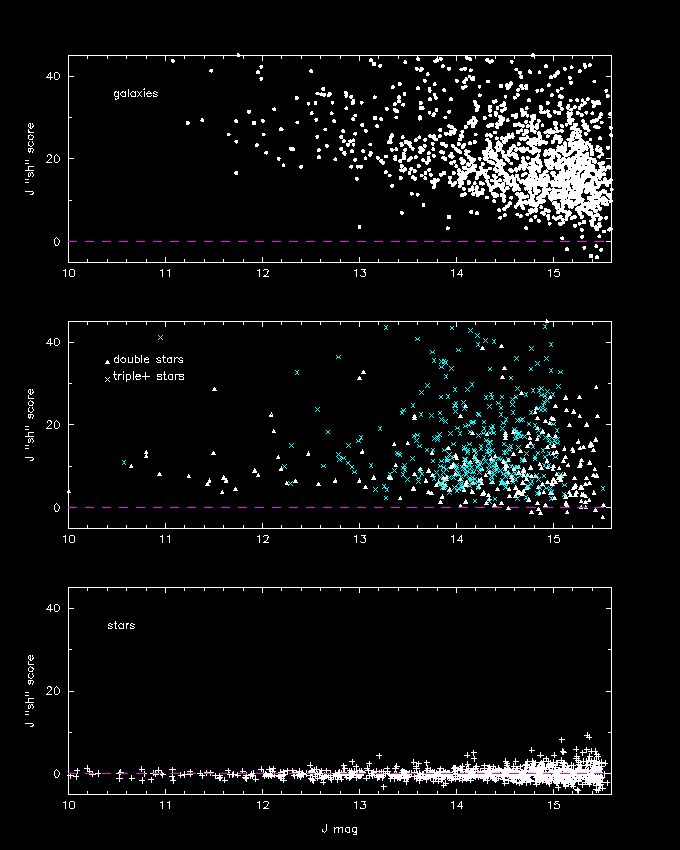{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}